Funzionamento del processo di failover
Failover di produzione
Dal momento della creazione, un server di ripristino rimane in modalità Standby. La macchina virtuale corrispondente non esiste fino a quando non viene avviato il failover. Prima di avviare il processo di failover, è necessario creare almeno un backup dell'immagine del disco (con un volume avviabile) del sistema originale.
All'avvio del processo di failover, viene selezionato il punto di ripristino del sistema originale dal quale verrà creata la macchina virtuale con i parametri predefiniti. L'operazione di failover utilizza la funzionalità di esecuzione della macchina virtuale da un backup. Il server di ripristino entra nello stato di transizione denominato Finalizzazione. Il processo implica il trasferimento dei dischi virtuali del server dall'archivio di backup (archivio cold) all'archivio di disaster recovery (archivio hot). Durante la finalizzazione il server è accessibile e funzionale, sebbene con prestazioni inferiori al normale. Una volta completata la finalizzazione, le prestazioni del server torneranno alla normalità. Lo stato del server passa a Failover. Il carico di lavoro viene trasferito dal sistema originale al server di ripristino nel sito cloud.
Se il server di ripristino include un agente di protezione, il servizio agente viene arrestato per evitare interferenze, ad esempio l'avvio di un backup o la creazione di report di stato non aggiornati nel componente di backup.
Il diagramma sottostante mostra i processi di failover e failback.
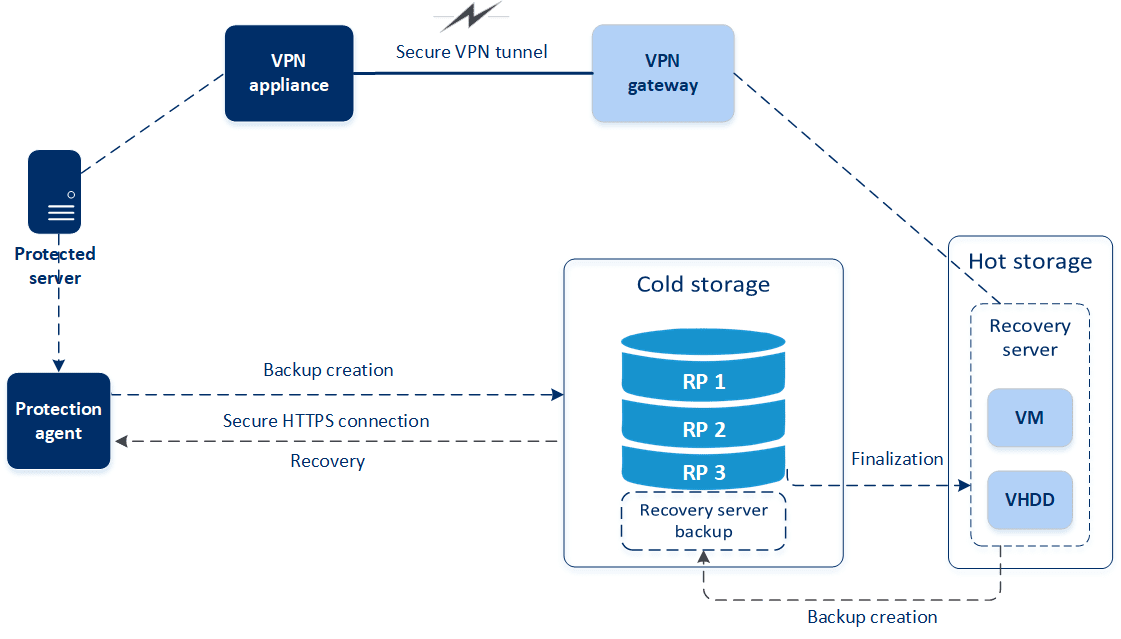
Prova failover
Durante un failover di prova, la virtual machine non viene finalizzata. Ciò significa che l'agente legge il contenuto dei dischi virtuali direttamente dal backup, ovvero accede in modo casuale alle varie parti del backup. Per ulteriori informazioni sul processo di failover di prova, vedere Esecuzione di un failover di prova.